Sep 12, 2010
Thanks to feedjack, I'm able to keep
in sync with 120 feeds (many of them, like slashdot or
reddit, being an aggregates as well), as of
today. Quite a lot of stuff I couldn't even imagine handling a year ago, and a
good aggregator definitely helps, keeping all the info just one click away.
And every workstation-based (desktop) aggregator I've seen is a fail:
- RSSOwl. Really nice interface and very
powerful. That said, it eats more ram than a firefox!!! Hogs CPU till the
whole system stutters, and eats more of it than every other app I use combined
(yes, including firefox). Just keeping it in the background costs 20-30% of
dualcore cpu. Changing "show new" to "show all" kills the system ;)
- liferea. Horribly slow, interface hangs on any
action (like fetching feed "in the background"), hogs cpu just as RSSOwl and
not quite as feature-packed.
- Claws-mail's RSSyl. Quite nice
resource-wise and very responsive, unlike dedicated software (beats me
why). Pity it's also very limited interface-wise and can't reliably keep track
of many of feeds by itself, constantly loosing a few if closed non-properly
(most likely it's a claws-mail fault, since it affects stuff like nntp as
well).
- Emacs' gnus and newsticker. Good for a feed or two, epic fail in every way
with more dozen of them.
- Various terminal-based readers. Simply intolerable.
Server-based aggregator on the other hand is a bliss - any hoards of stuff as
you want it, filtered, processed, categorized and re-exported to any format
(same rss, but not a hundred of them, for any other reader works as well) and
I don't give a damn about how many CPU-hours it spends doing so (yet it tend
to be very few, since processing and storage is done via production-grade
database and modules, not some crappy ad-hoc wheel re-invention).
And it's simple as a doorknob, so any extra functionality can be added with no
effort.
Maybe someday I'll get around to use something like Google Reader, but it's
still one hell of a mess, and it's no worse than similar web-based services out
there. So much for the cloud services. *sigh*
Sep 09, 2010
Ok, almost one month of glusterfs
was too much for me to handle. That was an epic fail ;)
Random errors on start (yeah, just restart nodes a few times and it'll be
fine) and during operation (same ESTALE, EIOs for whole mount, half of files
just vanishing) seem to be a norm for it. I mean, that's with a perfectly sane
and calm conditions - everything works, links stable.
A bit complicated configurations like server-side replication seem to be the
cause of these, sometimes to the point when the stuff just gives ESTALE in
100% cases right from the start w/o any reason I can comprehend. And adding a
third node to the system just made things worse and configuration files are
even more scary.
Well, maybe I'm just out of luck or too brain-dead for it, whatever.
So, moving on, I've tried (although briefly) ceph.
Being in mainline kernel, and not just the staging part, I'd expected it to be
much less work-in-progress, but as it is, it's very raw, to the point that
x86_64 monitor daemon just crashes upon receiving data from plain x86. Interface
is a bunch of simple shell scripts, fairly opaque operation, and the whole thing
is built on such crap as boost.
Managed to get it running with two nodes, but it feels like the end of the
world - one more kick and it all falls to pieces. Confirmed by the reports all
over the mailing list and #ceph.
In-kernel and seemingly fast is a good mix though, so I may get back to it
eventually, but now I'd rather prefer to settle on something that actually
works.
Next thing in my sight was tahoe-lafs, but it still
lacks normal posix-fs interface layer, sftp interface being totally unusable on
1.8.0c3 - no permissions, cp -R fails w/ I/O error, displayed data in
inconsistent even with locally-made changes, and so on. A pity, whole system
design looks very cool, with raid5-like "parity" instead of plain chunk
replication, and it's python!
Thus I ended up with MooseFS.
First thing to note here is incredibly simple and yet infinitely more powerful
interface that probably sold me the fs right from the start.
None of this configuration layers hell of gluster, just a line in hosts (so
there's no need to tweak configs at all!) plus a few about what to export
(subtrees-to-nets, nfs style) and where to put chunks (any fs as a simple
backend key-value storage), and that's about it.
Replication? Piece a cake, and it's configured on per-tree basis, so important
or compact stuff can have one replication "goal" and some heavy trash in the
neighbor path have no replication at all. No chance of anything like this with
gluster and it's not even documented for ceph.
Performance is totally I/O and network bound (which is totally not-the-case with
tahoe, for instance), so no complaints here as well.
One more amazing thing is how simple and transparent it is:
fraggod@anathema:~% mfsgetgoal tmp/db/softCore/_nix/os/systemrescuecd-x86-1.5.8.iso
tmp/db/softCore/_nix/os/systemrescuecd-x86-1.5.8.iso: 2
fraggod@anathema:~% mfsfileinfo tmp/db/softCore/_nix/os/systemrescuecd-x86-1.5.8.iso
tmp/db/softCore/_nix/os/systemrescuecd-x86-1.5.8.iso:
chunk 0: 000000000000CE78_00000001 / (id:52856 ver:1)
copy 1: 192.168.0.8:9422
copy 2: 192.168.0.11:9422
chunk 1: 000000000000CE79_00000001 / (id:52857 ver:1)
copy 1: 192.168.0.10:9422
copy 2: 192.168.0.11:9422
chunk 2: 000000000000CE7A_00000001 / (id:52858 ver:1)
copy 1: 192.168.0.10:9422
copy 2: 192.168.0.11:9422
chunk 3: 000000000000CE7B_00000001 / (id:52859 ver:1)
copy 1: 192.168.0.8:9422
copy 2: 192.168.0.10:9422
chunk 4: 000000000000CE7C_00000001 / (id:52860 ver:1)
copy 1: 192.168.0.10:9422
copy 2: 192.168.0.11:9422
fraggod@anathema:~% mfsdirinfo tmp/db/softCore/_nix/os
tmp/db/softCore/_nix/os:
inodes: 12
directories: 1
files: 11
chunks: 175
length: 11532174263
size: 11533462528
realsize: 23066925056
And if that's not enough, there's even a cow snaphots, trash bin with a
customizable grace period and a special attributes for file caching and
ownership, all totally documented along with the architectural details in
manpages and on the project site.
Code is plain C, no shitload of deps like boost and lib*whatevermagic*, and
it's really lite. Whole thing feels like a simple and solid design, not some
polished turd of a *certified professionals*.
Yes, it's not truly-scalable, as there's a master host (with optional
metalogger failover backups) with fs metadata, but there's no chance it'll be
a bottleneck in my setup and comparing to a "no-way" bottlenecks of other
stuff, I'd rather stick with this one.
MooseFS has yet to pass the trial of time on my makeshift "cluster", yet none of
the other setups went (even remotely) as smooth as this one so far, thus I feel
pretty optimistic about it.
Aug 15, 2010
Hardware
I'd say "every sufficiently advanced user is indistinguishable from a
sysadmin" (yes, it's a play on famous Arthur C Clarke's quote), and it doesn't
take much of "advanced" to come to a home-server idea.
And I bet the main purpose for most of these aren't playground, p2p client or
some http/ftp server - it's just a storage. Serving and updating the stored
stuff is kinda secondary.
And I guess it's some sort of nature law that any storage runs outta free
space sooner or later. And when this happens, just buying more space seem to
be a better option than cleanup because a) "hey, there's dirt-cheap 2TB
harddisks out there!" b) you just get used to having all that stuff at
packet's reach.
Going down this road I found myself out of connectors on the motherboard
(which is fairly spartan
D510MO miniITX)
and the slots for an extension cards (the only PCI is used by dual-port nic).
So I hooked up two harddisks via usb, but either the usb-sata controllers or
usb's on the motherboard were faulty and controllers just hang with both leds
on, vanishing from the system. Not that it's a problem - just mdraid'ed them
into raid1 and when one fails like that, I just have to replug it and start
raid recovery, never losing access to the data itself.
Then, to extend the storage capacity a bit further (and to provide a backup to
that media content) I just bought +1 miniITX unit.
Now, I could've mouned two NFS'es from both units, but this approach has
several disadvantages:
- Two mounts instead of one. Ok, not a big deal by itself.
- I'd have to manage free space on these by hand, shuffling subtrees between
them.
- I need replication for some subtrees, and that complicates the previous point
a bit further.
- Some sort of HA would be nice, so I'd be able to shutdown one replica and
switch to using another automatically.
The obvious improvement would be to use some distributed network filesystem,
and pondering on the possibilities I've decided to stick with the glusterfs
due to it's flexible yet very simple "layer cake" configuration model.
Oh, and the most important reason to set this whole thing up - it's just fun ;)
The Setup
Ok, what I have is:
- Node1
- physical storage (raid1) "disk11", 300G, old and fairly "valuable" data
(well, of course it's not "valuable", since I can just re-download it all
from p2p, but I'd hate to do that)
- physical disk "disk12", 150G, same stuff as disk11
- Node2
- physical disk "disk2", 1.5T, blank, to-be-filled
What I want is one single network storage, with db1 (disk11 + disk12) data
available from any node (replicated) and new stuff which won't fit onto this
storage should be writen to db2 (what's left of disk2).
With glusterfs there are several ways to do this:
Scenario 1: fully network-aware client.
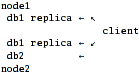
That's actually the simplest scenario - glusterfsd.vol files on "nodes" should
just export local disks and client configuration ties it all together.
Pros:
- Fault tolerance. Client is fully aware of the storage hierarchy, so if one
node with db1 is down, it will just use the other one.
- If the bandwidth is better than disk i/o, reading from db1 can be potentially
faster (dunno if glusterfs allows that, actually), but that's not the case,
since "client" is one of the laptops and it's a slow wifi link.
Cons:
- Write performance is bad - client has to push data to both nodes, and that's a
- big minus with my link.
Scenario 2: server-side replication.
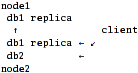
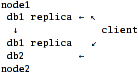
Here, "nodes" export local disks for each other and gather local+remote db1 into
cluster/replicate and then export this already-replicated volume. Client just
ties db2 and one of the replicated-db1 together via nufa or distribute layer.
Pros:
Cons:
- Single point of failure, not only for db2 (which is natural, since it's not
replicated), but for db1 as well.
Scenario 3: server-side replication + fully-aware client.
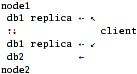
db1 replicas are synced by "nodes" and client mounts all three volumes (2 x db1,
1 x db2) with either cluster/unify layer and nufa scheduler (listing both db1
replicas in "local-volume-name") or cluster/nufa.
That's the answer to obvious question I've asked myself after implementing
scenario 2: "why not get rid of this single_point_of_failure just by using
not single, but both replicated-db1 volumes in nufa?"
In this case, if node1 goes down, client won't even notice it! And if that
happens to node2, files from db2 just disappear from hierarchy, but db1 will
still remain fully-accessible.
But there is a problem: cluster/nufa has no support for multiple
local-volume-name specs. cluster/unify has this support, but requires it's ugly
"namespace-volume" hack. The solution would be to aggregate both db1's into a
distribute layer and use it as a single volume alongside db2.
With aforementioned physical layout this seem to be just the best all-around
case.
Pros:
- Best performance and network utilization.
Cons:
Implementation
So, scenarios 2 and 3 in terms of glusterfs, with the omission of different
performance, lock layers and a few options, for the sake of clarity:
node1 glusterfsd.vol:
## db1: replicated node1/node2
volume local-db1
type storage/posix
option directory /srv/storage/db1
end-volume
# No client-caches here, because ops should already come aggregated
# from the client, and the link between servers is much fatter than the client's
volume node2-db1
type protocol/client
option remote-host node2
option remote-subvolume local-db1
end-volume
volume composite-db1
type cluster/replicate
subvolumes local-db1 node2-db1
end-volume
## db: linear (nufa) db1 + db2
## export: local-db1 (for peers), composite-db1 (for clients)
volume export
type protocol/server
subvolumes local-db1 composite-db1
end-volume
node2 glusterfsd.vol:
## db1: replicated node1/node2
volume local-db1
type storage/posix
option directory /srv/storage/db1
end-volume
# No client-caches here, because ops should already come aggregated
# from the client, and the link between servers is much fatter than the client's
volume node1-db1
type protocol/client
option remote-host node1
option remote-subvolume local-db1
end-volume
volume composite-db1
type cluster/replicate
subvolumes local-db1 node1-db1
end-volume
## db2: node2
volume db2
type storage/posix
option directory /srv/storage/db2
end-volume
## db: linear (nufa) db1 + db2
## export: local-db1 (for peers), composite-db1 (for clients)
volume export
type protocol/server
subvolumes local-db1 composite-db1
end-volume
client (replicated to both nodes):
volume node1-db1
type protocol/client
option remote-host node1
option remote-subvolume composite-db1
end-volume
volume node2-db1
type protocol/client
option remote-host node2
option remote-subvolume composite-db1
end-volume
volume db1
type cluster/distribute
option remote-subvolume node1-db1 node2-db1
end-volume
volume db2
type protocol/client
option remote-host node2
option remote-subvolume db2
end-volume
volume db
type cluster/nufa
option local-volume-name db1
subvolumes db1 db2
end-volume
Actually there's one more scenario I thought of for non-local clients - same
as 2, but pushing nufa into glusterfsd.vol on "nodes", thus making client
mount single unified volume on a single host via single port in a single
connection.
Not that I really need this one, since all I need to mount from external
networks is just music 99.9% of time, and
NFS + FS-Cache
offer more advantages there, although I might resort to it in the future, when
music won't fit to db1 anymore (doubt that'll happen anytime soon).
P.S.
Configs are fine, but the most important thing for setting up glusterfs are
these lines:
node# /usr/sbin/glusterfsd --debug --volfile=/etc/glusterfs/glusterfsd.vol
client# /usr/sbin/glusterfs --debug --volfile-server=somenode /mnt/tmp
Jun 14, 2010
Guess being a long user of stuff like OpenSSH,
iproute2
and VDE rots your brain - you start thinking
that building any sort of tunnel is a bliss. Well, it's not. At least not "any
sort".
This day I've dedicated to set up some basic IPSec tunnel and at first that
seemed an easy task - it's long ago in kernel (
kame
implementation, and it's not the only one for linux), native for IPv6 (which I
use in a local network), has quite a lot of publicity (and guides), it's open
(and is quite simple, even with IKE magic) and there are at least three major
userspace implementations:
openswan,
ipsec-tools (racoon, kame) and
Isakmpd. Hell, it's even supported on Windows. What's more to ask for?
Well, prehaps I made a bad decision starting with openswan and "native" kame
NETKEY, but my experience wasn't quite a nice one.
I chose openswan because it looks like more extensive implementation than the
rest, and is supported by folks like Red Hat, plus it is fairly up to date and
looks constantly developed. Another cherry in it was apparent smartcard support
via nss now and opensc in the past.
Latest version of it in ebuild form (which isn't quite enough for me anyway,
since I use exheres these days) is 2.6.23. That's more than half a year old,
and even that one is masked in gentoo due to apparent bugs and the ebuild is
obviously blind-bumped from some previous version, since it doesn't take
things like opensc->nss move (finalized in 2.6.23) into account.
Okay, hacking my own ebuild and exheres for it was fun enough, at least I've
got a firm grasp of what it's capable of, but seeing pure-Makefile build
system and hard-coded paths in such a package was a bit unexpected. Took me
some time to deal with include paths, then lib paths, then it turned out to
had an
open bug which prevents
it's build on linux (wtf!?), and then it crashes on install phase due to some
ever-crappy XML stuff.
At least the docs are good enough (even though it's not easy to build them),
so I set up an nss db, linked smartcard to it, and got a... segfault? Right
on ipsec showhostkey? Right, there's
this bug
in 2.6.26, although in my case it's probably another one, since the patch
doesn't fixes the problem. Great!
Ok, gdb showed that it's something like get-nss-password failing (although it
should be quite a generic interface, delegated from nss), even with
nsspassword in place and nss itself working perfectly.
Scratch that, simple nss-generated keys (not even certificates) as described
in the
most basic tutorial, and now it's pluto
daemon crashing with just a "Jun 14 15:40:25 daemon.err<27>
ipsec__plutorun[-]: /usr/lib/ipsec/_plutorun: line 244: 6229 Aborted ..."
line in syslog as soon as both ends off tunnel are up.
Oh, and of course it messes up the connection between hosts in question, so it
wouldn't be too easy to ssh between them and debug the problem.
Comparing to ssh or pretty much any tunneling I've encountered to this point,
it's still quite a remarkably epic fail. Guess I'll waste a bit more time on
this crap, since success seems so close, but it's quite amazing how crappy such
projects can still be these days. Of course, at least it's free, right?
Jun 13, 2010
There's one great app -
bournal ("when
nobody cares what you have to say!"). Essentialy it's a bash script, providing
a simple interface to edit and encrypt journal entries.
Idea behind it is quite opposite of blogging - keep your thoughts as far away
from everyone as possible. I've used the app for quite a while, ever since
I've noticed it among freshmeat release announcements. It's useful to keep
some thoughts or secrets (like keys or passwords) somewhere, aside from the
head, even if you'd never read these again.
Anyway, encryption there is done by the means of ccrypt utility, which is sorta CLI for openssl. I don't get the rationale behind using it instead
of openssl directly (like "openssl enc ..."), and there are actually even better
options, like gnupg, which won't need a special logic
to keep separate stream-cipher password, like it's done in bournal.
So today, as I needed bournal on exherbo laptop, I've faced the need to get
ccrypt binary just for that purpose again. Worse yet, I have to recall and
enter a password I've used there, and I don't actually need it to just encrypt
an entry... as if assymetric encryption, gpg-agent, smartcards and all the
other cool santa helpers don't exist yet.
I've decided to hack up my "ccrypt" which will use all-too-familiar gpg and
won't ask me for any passwords my agent or scd already know, and in an hour or
so, I've succeeded.
And
here goes - ccrypt, relying
only on "gpg -e -r $EMAIL" and "gpg -d". EMAIL should be in the env, btw.
It actually works as ccencrypt, ccdecrypt, ccat as well, and can do recursive
ops just like vanilla ccrypt, which is enough for bournal.
Jun 05, 2010
If you're downloading stuff off the 'net via bt like me, then TPB is probably quite a familiar place to you.
Ever since the '09 trial there were a problems with TPB trackers
(tracker.thepiratebay.org) - the name gets inserted into every .torrent yet it
points to 127.0.0.1.
Lately, TPB offshot, tracker.openbittorrent.com suffers from the same problem
and actually there's a lot of other trackers in .torrent files that point
either at 0.0.0.0 or 127.0.0.1 these days.
As I use
rtorrent, I have an issue with
this - rtorrent seem pretty dumb when it comes to tracker filtering so it
queries all of them on a round-robin basis, without checking where it's name
points to or if it's down for the whole app uptime, and queries take quite a
lot of time to timeout, so that means at least two-minute delay in starting
download (as there's TPB trackers first), plus it breaks a lot of other things
like manual tracker-cycling ("t" key), since it seem to prefer only top-tier
trackers and these are 100% down.
Now the problem with http to localhost can be solved with the firewall, of
course, although it's an ugly solution, and 0.0.0.0 seem to fail pretty fast
by itself, but stateless udp is still a problem.
Another way to tackle the issue is probably just to use a client that is
capable of filtering the trackers by ip address, but that probably means some
heavy-duty stuff like azureus or vanilla bittorrent which I've found pretty
buggy and also surprisingly heavy in the past.
So the easiest generic solution (which will, of course, work for rtorrent) I've
found is just to process the .torrent files before feeding them to the leecher
app. Since I'm downloading these via firefox exclusively, and there I use
FlashGot (not the standard "open with" interface since
I also use it to download large files on remote machine w/o firefox, and afaik
it's just not the way "open with" works) to drop them into an torrent bin via
script, it's actually a matter of updating the link-receiving script.
Bencode is not a mystery, plus it's
pure-py implementation is actually the reference one, since it's a part of
original python bittorrent client, so all I basically had to do is to rip
bencode.py from it and paste the relevant part into the script.
The right way might've been to add dependency on the whole bittorrent client,
but it's an overkill for such a simple task plus the api itself seem to be
purely internal and probably a subject to change with client releases anyway.
So, to the script itself...
# URL checker
def trak_check(trak):
if not trak: return False
try: ip = gethostbyname(urlparse(trak).netloc.split(':', 1)[0])
except gaierror: return True # prehaps it will resolve later on
else: return ip not in ('127.0.0.1', '0.0.0.0')
# Actual processing
torrent = bdecode(torrent)
for tier in list(torrent['announce-list']):
for trak in list(tier):
if not trak_check(trak):
tier.remove(trak)
# print >>sys.stderr, 'Dropped:', trak
if not tier: torrent['announce-list'].remove(tier)
# print >>sys.stderr, 'Result:', torrent['announce-list']
if not trak_check(torrent['announce']):
torrent['announce'] = torrent['announce-list'][0][0]
torrent = bencode(torrent)
That, plus the simple "fetch-dump" part, if needed.
No magic of any kind, just a plain "announce-list" and "announce" urls check,
dropping each only if it resolves to that bogus placeholder IPs.
I've wanted to make it as light as possible so no logging or optparse/argparse
stuff I tend cram everywhere I can, and the extra and heavy imports like
urllib/urllib2 are conditional as well. The only dependency is python (>=2.6)
itself.
Basic use-case is one of these:
% brecode.py < /path/to/file.torrent > /path/to/proccessed.torrent
% brecode.py http://tpb.org/torrents/myfile.torrent > /path/to/proccessed.torrent
% brecode.py http://tpb.org/torrents/myfile.torrent\
-r http://tpb.org/ -c "...some cookies..." -d /path/to/torrents-bin/
All the extra headers like cookies and referer are optional, so is the
destination path (dir, basename is generated from URL). My use-case in FlashGot
is this: "[URL] -r [REFERER] -c [COOKIE] -d /mnt/p2p/bt/torrents"
And there's the script itself.
Quick, dirty and inconclusive testing showed almost 100 KB/s -> 600 KB/s
increase on several different (two successive tests on the same file even with
clean session are obviously wrong) popular and unrelated .torrent files.
That's pretty inspiring. Guess now I can waste even more time on the TV-era
crap than before, oh joy ;)
May 08, 2010
From time to time I accidentally bump into new releases from the artists/bands
I listen to. Usually it happens on the web, since I don't like random radio
selections much, and quite a wide variety of stuff I like seem to ensure that
my
last.fm radio is a mess.
So, after accidentally seeing a few new albums for my collection, I've decided
to remedy the situation somehow.
Naturally, subscribing to something like an unfiltered flow of new music
releases isn't an option, but no music site other than last.fm out there knows
the acts in my collection to track updates for those, and last.fm doesn't seem
to have the functionality I need - just to list new studio releases from the
artists I listened to beyond some reasonable threshold, or I just haven't been
able to find it.
I thought of two options.
First is writing some script to submit my watch-list to some music site, so
it'd notify me somehow about updates to these.
Second is to query the updates myself, either through some public-available
APIs like last.fm, cddb, musicbrainz or even something like public atom feeds
from a music portals. It seemed like a pretty obvious idea, btw, yet I've
found no already-written software to do the job.
First one seemed easier, but not as entertaining as the second, plus I have
virtually no knowledge to pick a site which will be best-suited for that (and
I'd hate to pick a first thing from the google), and I'd probably have to
post-process what this site feeds me anyway. I've decided to stick with the
second way.
The main idea was to poll list of releases for every act in my collection, so
the new additions would be instantly visible, as they weren't there before.
Such history can be kept in some db, and an easy way to track such flow would
be just to dump db contents, ordered by addition timestamp, to an atom feed.
Object-db to a web content is a typical task for a web framework, so I chose to
use django as a basic template for the task.
Obtaining list of local acts for my collection is easy, since I prefer not to
rely on tags much (although I try to have them filled with the right data as
well), I keep a strict "artist/year_album/num_-_track" directory tree, so
it takes one readdir with minor post-processing for the names - replace
underscores with spaces, "..., The" to "The ...", stuff like that.
Getting a list of an already-have releases then is just one more listing for
each of the artists' dir.
To get all existing releases, there's cddb, musicbrainz and last.fm and co
readily available.
I chose to use
musicbrainz db (at least as the
first source), since it seemed the most fitting to my purposes, shouldn't be
as polluted as last.fm (which is formed arbitrarily from the tags ppl have in
the files, afaik) and have clear studio-whateverelse distinction.
There's handy
official py-api readily available, which I
query by name for the act, then query it (if found) for available releases
("release" term is actually from there).
The next task is to compare two lists to drop the stuff I already have (local
albums list) from the fetched list.
It'd also be quite helpful to get the release years, so all the releases which
came before the ones in the collection can be safely dropped - they certainly
aren't new, and there should actually be lots of them, much more than truly
new ones. Mbz-db have "release events" for that, but I've quickly found that
there's very little data in that section of db, alas. I wasn't happy about
dropping such an obviously-effective filter so I've hooked much fatter last.fm
db to query for found releases, fetching release year (plus some descriptive
metadata), if there's any, and it actually worked quite nicely.
Another thing to consider here is a minor name differences - punctuation,
typos and such. Luckily, python has a nice
difflib right in the stdlib, which can
compare the strings to get the fuzzy (to a defined threshold) matches, easy.
After that comes db storage, and there's not much to implement but a simple
ORM-model definition with a few unique keys and the django will take care of the
rest.
The last part is the data representation.
No surprises here either, django has
syndication feed framework module,
which can build db-to-feed mapping in a three lines of code, which is almost
too easy and non-challenging, but oh well...
Another great view into db data is the
django admin module,
allowing pretty filtering, searching and ordering, which is nice to have
beside the feed.
One more thing I've thought of is the caching - no need to strain free databases
with redundant queries, so the only non-cached data from these are the lists of
the releases which should be updated from time to time, the rest can be kept in
a single "seen" set of id's, so it'd be immediately obvious if the release was
processed and queried before and is of no more interest now.
To summarize: the tools are django,
python-musicbrainz2 and
pylast; last.fm and
musicbrainz - the data sources (although I might
extend this list); direct result - this feed.
Gave me several dozens of a great new releases for several dozen acts (out of
about 150 in the collection) in the first pass, so I'm stuffed with a new yet
favorite music for the next few months and probably any forseeable future (due
to cron-based updates-grab).
Problem solved.
Code is here, local acts'
list is provided by a simple generator that should be easy to replace for any
other source, while the rest is pretty simple and generic.
Feed (feeds.py) is hooked via django URLConf (urls.py) while the cron-updater
script is bin/forager.py. Generic settings like cache and api keys are in the
forager-app settings.py. Main processing code reside in models.py (info update
from last.fm) and mbdb.py (release-list fetching). admin.py holds a bit of
pretty-print settings for django admin module, like which fields should be
displayed, made filterable, searchable or sortable. The rest are basic django
templates.
Apr 25, 2010
So far I like
exherbo way of package management and
base system layout.
I haven't migrated my desktop environment to it yet, but I expect it shouldn't
be a problem, since I don't mind porting all the stuff I need either from
gentoo or writing exheres for all I need from scratch.
First challenge I've faced though was due to my late addiction to
fossil scm, which doesn't seem to neither be in any of
exherbo repos listed in unavailable meta-repository, nor have a syncer for
paludis, so I wrote my own dofossil syncer and
created the repo.
Syncer should support both fossil+http:// and fossil+file:// protocols and
tries to rebuild repository data from artifacts' storage, should it encounter
any errors in process.
Repository, syncer and some instructions are here.
Thought I'd give google some keywords, should someone be looking for the same
thing, although I'd probably try to push it into paludis and/or "unavailable"
repo, when (and if) I'll get a bit more solid grasp on exherbo concepts.
Apr 25, 2010
While I'm on a vacation, I've decided to try out new distro I've been meaning
to for quite awhile -
exherbo.
Mostly it's the same source-based
gentoo-linux
derivative, yet it's not cloned from gentoo, like
funtoo or
sabayon, but built
from scratch by the guys who've seen gentoo and it's core concepts (like
portage or baselayout) as quite a stagnant thing.
While I don't share much of the disgust they have for gentoo legacy, the ideas
incorporated in that distro sound quite interesting, but I digress...
I don't believe in fairly common practice of "trying out" something new on a
VM - it just don't work for me, probably because I see it as a stupid and
posintless thing on some subconscious level, so I've decided to put it onto one
of my two laptops, which kinda needed a good cleanup anyway.
While at it, I thought it'd be a good idea to finally dump that stupid practice
of entering fs-password on boot, yet I did like the idea of encrypted fs,
especially in case of laptop, so I've needed to devise reasonably secure yet
paswordless boot method.
I use in-kernel LUKS-enabled dm-crypt (with the help of cryptsetup tool), and I need some initrd (or init-fs)
for LVM-root anyway.
There are lots of guides on how to do that with a key from a flash drive but I
don't see it particulary secure, since the key can always be copied from a
drive just about anywhere, plus I don't trust the flash drives much as they
seem to fail me quite often.
As an alternative to that, I have a smartcard-token, which can have a key that
can't be copied in any way.
Problem is, of course, that I need to see some key to decrypt filesystem, so
my idea was to use that key to sign some temporary data which then used to as
an encryption secret.
Furthermore, I thought it'd be nice to have a "dynamic key" that'd change on
every bootup, so even if anything would be able to snatch it from fs and use
token to sign it, that data would be useless after a single reboot.
Initrd software is obviously a
busybox, lvm and a
smartcard-related stuff.
Smartcard I have is Alladin eToken PRO 64k, it works fine with
OpenSC but not via
pcsc-lite, which seem to be preferred hardware
abstraction, but with
openct, which
seems a bit obsolete way. I haven't tried pcsc-lite in quite a while though,
so maybe now it supports eToken as well, but since openct works fairly stable
for me, I thought I'd stick with it anyway.
Boot sequence comes down to these:
- Mount pseudofs like proc/sys, get encrypted partition dev and real-rootfs
signature (for findfs tool, like label or uuid) from cmdline.
- Init openct, find smartcard in /sys by hardcoded product id and attach it to
openct.
- Mount persistent key-material storage (same /boot in my case).
- Read "old" key, replace it with a hashed version, aka "new key".
- Sign old key using smartcard, open fs with the resulting key.
- Drop this key from LUKS storage, add a signed "new" key to it.
- Kill openct processes, effectively severing link with smartcard.
- Detect and activate LVM volume groups.
- Find (findfs) and mount rootfs among currently-available partitions.
- Umount proc/sys, pivot_root, chroot.
- Here comes the target OS' init.
Took me some time to assemble and test this stuff, although it was fun playing
with linux+busybox mini-OS. Makes me somewhat wonder about what takes several
GiBs of space in a full-fledged OS when BB contains pretty much everything in
less than one MiB ;)
And it's probably a good idea to put some early check of /boot partition
(hashes, mounts, whatever) into booted OS init-scripts to see if it was not
altered in any significant way. Not really a guarantee that something nasty
weren't done to it (and then cleaned up, for example) plus there's no proof that
actual OS was booted up from it and the kernel isn't tainted in some malicious
way, but should be enough against some lame tampering or pranks, should these
ever happen.
Anyway, here's the repo with all the initrd
stuff, should anyone need it.
Apr 17, 2010
I'm a happy
git user for several years now, and the
best thing about it is that I've learned how VCS-es, and git in particular,
work under the hood.
It expanded (and in most aspects probably formed) my view on the time-series
data storage - very useful knowledge for wide range of purposes from log or
configuration storage to snapshotting, backups and filesystem
synchronisation. Another similar revelation in this area was probably
rrdtool, but still on much smaller scale.
Few years back, I've kept virtually no history of my actions, only keeping my
work in
CVS/
SVN, and even that was just for ease of
collaboration.
Today, I can easily trace, sync and transfer virtually everything that changes
and is important in my system - the code I'm working on, all the configuration
files, even auto-generated ones, tasks' and thoughts' lists, state-description
files like lists of installed packages (local sw state) and gentoo-portage
tree (global sw state), even all the logs and binary blobs like rootfs in
rsync-hardlinked backups for a few past months.
Git is a great help in these tasks, but what I feel lacking there is a
first - common timeline (spanning both into the past and the future) for
all these data series, and second - documentation.
Solution to the first one I've yet to find.
Second one is partially solved by commit-msgs, inline comments and even this
blog for the past issues and simple todo-lists (some I keep in plaintext, some
in tudu app) for the future.
Biggest problem I see here is the lack of consistency between all these:
todo-tasks end up as dropped lines in the git-log w/o any link to the past
issues or reverse link to the original idea or vision, and that's just the
changes.
Documentation for anything more than local implementation details and it's
history is virtually non-existant and most times it takes a lot of effort and
time to retrace the original line of thought, reasoning and purpose behind the
stuff I've done (and why I've done it like that) in the past, often with the
considerable gaps and eventual re-invention of the wheels and pitfalls I've
already done, due to faulty biological memory.
So, today I've decided to scour over the available project and task management
software to find something that ties the vcs repositories and their logs with
the future tickets and some sort of expanded notes, where needed.
Starting point was actually the
trac, which
I've used quite extensively in the past and present, and is quite fond of it's
outside simplicity yet fully-featured capabilities as both wiki-engine and
issue tracker. Better yet, it's py and can work with vcs.
The downside is that it's still a separate service and web-based one at that,
meaning that it's online-only, and that the content is anchored to the server
I deploy it to (not to mention underlying vcs). Hell, it's centralized and
laggy, and ever since git's branching and merging ideas of decentralized work
took root in my brain, I have issue with that.
It just looks like a completely wrong approach for my task, yet I thought that I
can probably tolerate that if there are no better options and then I've stumbled
upon Fossil VCS.
The name actually rang a bell, but from a
9p universe, where it's a name
for a vcs-like filesystem which was (along with venti, built on top of it) one
of two primary reasons I've even looked into
plan9 (the other being its 9p/styx
protocol).
Similary-named VCS haven't disappointed me as well, at least conceptually. The
main win is in the integrated ticket system and wiki, providing just the thing
I need in a distributed versioned vcs environment.
Fossil's overall design principles and concepts (plus this) are
well-documented on it's site (which is a just
a fossil repo itself), and the catch-points for me were:
- Tickets and wiki, of course. Can be edited locally, synced,
distributed, have local settings and appearance, based on tcl-ish
domain-specific
language.
- Distributed nature, yet rational position of authors on
centralization and synchronization topic.
- All-in-one-static-binary approach! Installing hundreds of git
binaries to every freebsd-to-debian-based system, was a pain, plus
I've ended up with 1.4-1.7 version span and some features (like "add
-p") depend on a whole lot of stuff there, like perl and damn lot of
it's modules. Unix-way is cool, but that's really more portable and
distributed-way-friendly.
- Repository in a single package, and not just a binary blob, but a
freely-browsable sqlite db. It certainly is a
hell lot more convenient than path with over nine thousand blobs with
sha1-names, even if the actual artifact-storage here is built
basically the same way. And the performance should be actually better
than the fs - with just index-selects BTree-based sqlite is as fast
as filesystem, but keeping different indexes on fs is by
sym-/hardlinking, and that's a pain that is never done right on fs.
- As simple as possible internal blobs' format.
- Actual symbolics and terminology. Git is a faceless tool, Fossil have
some sort of a style, and that's nice ;)
Yet there are some things I don't like about it:
- HTTP-only sync. In what kind of twisted world that can be better than
ssh+pam or direct access? Can be fixed with a wrapper, I guess, but
really, wtf...
- SQLite container around generic artifact storage. Artifacts are pure
data with a single sha1sum-key for it, and that is simple, solid and
easy to work with anytime, but wrapped into sqlite db it suddenly
depends on this db format, libs, command-line tool or language
bindings, etc. All the other tables can be rebuilt just from these
blobs, so they should be as accessible as possible, but I guess
that'd violate whole single-file design concept and would require a
lot of separate management code, a pity.
But that's nothing more than a few hours' tour of the docs and basic hello-world
tests, guess it all will look different after I'll use it for a while, which I'm
intend to do right now. In the worst case it's just a distributed issue
tracker + wiki with cli interface and great versioning support in one-file
package (including webserver) which is more than I can say about trac, anyway.