Apr 10, 2010
Last month I've been busy setting up a monitoring system at work.
Mostly it's the graphs with dynamic data like cpu/mem/io/net loads and
application-specific stats (which I'll probably get around to describing
sometime later), for which there is a nice RRD solutions (I've used
cacti +
snmpd +
my python
extensions +
pyrrd +
rrdtool directly), but there was also one specific
task of setting up websites' http-availability monitoring, spread on several
shared-hosting servers.
There's about 4k of such websites and the data needed is close to boolean -
whether site returns http code below 500 or it's considered "down", but it'd
have been nice to know the code it returns.
Plus, of course, this responses have to be logged, so availability for any
specific period can be calculated (in my case just as 1 - time_down /
time_total). And these shouldn't include random stuff like 503 "downtime"
because the poller got a bad luck on one poll or 500 because apache got a HUP
while processing a request (in theory, these shouldn't happen of course,
but...).
And on top of that, response delay have to be measured as well. And that is
data which should be averaged and selected on some non-trivial basis. Sites'
list changes on a daily basis, polled data should be closed to real-time, so
it's 5-10 minutes poll interval at most.
Clearly, it's time-series data yet rrd is unsuitable for the task - neither
it's well-suited for complex data analysis, nor it can handle dynamic
datasets. Creating a hundred rrds and maintaining the code for their
management on fs looks like a world of pain.
Plain-log approach looks highly unoptimal, plus it's a lot of processing and
logfile-management code.
Both approaches also needed some sort of (although trivial) network interface
to data as well.
SQL-based DB engines handle storage and some-criteria-based selection and have
an efficient network interface outta the box, so it wasn't much of a hard
choice. And the only decent DBs I know out there are PostgreSQL and Oracle,
sqlite or MySQL are rather limited solutions and I've never used
interbase/firebird.
4k*5min is a lot of values though, tens-hundreds of millions of them
actually, and RDBMS become quite sluggish on such amounts of data, so some
aggregation or processing was in order and that's what this entry's about.
First, I've needed to keep one list of domains to check.
These came from the individual hosts where they were, well, hosted, so poller
can periodically get this list and check all the domains there.
CREATE TABLE state_hoard.list_http_availability (
id serial NOT NULL,
target character varying(128) NOT NULL,
"domain" character varying(128) NOT NULL,
check_type state_hoard.check_type NOT NULL,
"timestamp" numeric,
source character varying(16),
CONSTRAINT state_ha__id PRIMARY KEY (id),
CONSTRAINT state_ha__domain_ip_check_type
UNIQUE (target, domain, check_type) );
It should probably be extended with other checks later on so there's check_type
field with enum like this:
CREATE TYPE state_hoard.check_type AS ENUM ('http', 'https');
Target (IP) and domain (hostname) are separate fields here, since dns data is
not to be trusted but the http request should have host-field to be processed
correctly.
Resulting table: 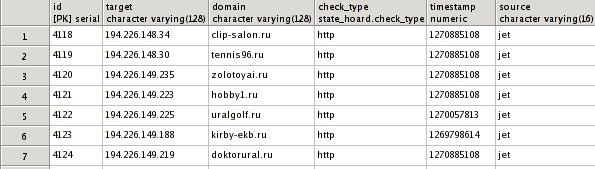
List is updated via third-party scripts which shouldn't care for internal db
structure even a little bit, so they only need to do insert/delete ops when
the list changes, so the db can take care of the rest, thanks to triggers.
Replace via delete/insert approach isn't an option here, since other tables
are linked vs this one, so update is the way.
CREATE OR REPLACE FUNCTION state_hoard.list_ha_replace()
RETURNS trigger AS
$BODY$
DECLARE
updated integer;
BEGIN
-- Implicit timestamping
NEW.timestamp := COALESCE( NEW.timestamp,
EXTRACT('epoch' FROM CURRENT_TIMESTAMP) );
UPDATE state_hoard.list_http_availability
SET timestamp = NEW.timestamp, source = NEW.source
WHERE domain = NEW.domain
AND target = NEW.target
AND check_type = NEW.check_type;
-- Check if the row still need to be inserted
GET DIAGNOSTICS updated = ROW_COUNT;
IF updated = 0
THEN RETURN NEW;
ELSE RETURN NULL;
END IF;
END;
$BODY$
LANGUAGE 'plpgsql' VOLATILE
COST 100;
CREATE TRIGGER list_ha__replace
BEFORE INSERT
ON state_hoard.list_http_availability
FOR EACH ROW
EXECUTE PROCEDURE state_hoard.list_ha_replace();
From there I had two ideas on how to use this data and store immediate
results, from the poller perspective:
- To replicate the whole table into some sort of "check-list", filling
fields there as the data arrives.
- To create persistent linked tables with polled data, which just
replaced (on unique-domain basis) with each new poll.
While former looks appealing since it allows to keep state in DB, not
the poller, latter provides persistent availability/delay tables and
that's one of the things I need.
CREATE TABLE state_hoard.state_http_availability (
check_id integer NOT NULL,
host character varying(32) NOT NULL,
code integer,
"timestamp" numeric,
CONSTRAINT state_ha__check_host PRIMARY KEY (check_id, host),
CONSTRAINT state_http_availability_check_id_fkey FOREIGN KEY (check_id)
REFERENCES state_hoard.list_http_availability (id) MATCH SIMPLE
ON UPDATE RESTRICT ON DELETE CASCADE );
CREATE TABLE state_hoard.state_http_delay (
check_id integer NOT NULL,
host character varying(32) NOT NULL,
delay numeric,
"timestamp" numeric,
CONSTRAINT state_http_delay_check_id_fkey FOREIGN KEY (check_id)
REFERENCES state_hoard.list_http_availability (id) MATCH SIMPLE
ON UPDATE NO ACTION ON DELETE CASCADE );
These can be thought of as an extensions of the main (list_http_availability)
table, containing "current state" columns for each polled domain, and when
domain is no longer polled, it gets dropped from these tables as well.
Poller just gets the list and inserts the values into these, w/o even having
permissions to alter the list itself.
Since these tables are for latest data, duplicate inserts should be
handled and timestamps can be generated implicitly.
For current-state table it's just a replace on each insert. PostgreSQL doesn't
have convenient "replace" statement like MySQL but the triggers can easily
compensate for that:
CREATE OR REPLACE FUNCTION state_hoard.state_ha_replace()
RETURNS trigger AS
$BODY$
BEGIN
-- Drop old record, if any
DELETE FROM state_hoard.state_http_availability WHERE check_id = NEW.check_id AND host = NEW.host;
-- Implicit timestamp setting, if it's omitted
NEW.timestamp := COALESCE(NEW.timestamp, EXTRACT('epoch' FROM CURRENT_TIMESTAMP));
RETURN NEW;
END;
$BODY$
LANGUAGE 'plpgsql' VOLATILE
COST 100;
CREATE TRIGGER state_ha__replace
BEFORE INSERT
ON state_hoard.state_http_availability
FOR EACH ROW
EXECUTE PROCEDURE state_hoard.state_ha_replace();
Individual http delays can have quite high entropy, since the http-response
processing in poller can't be truly asynchronous with such a number of hosts
and in fact it's a single-thread eventloop (twisted) anyway, so values here
are kept for some time, so they can be averaged later with a simple group-by.
Timestamp-based cleanup is built into the poller itself, so the trigger here
only fills implicit timestamps.
CREATE OR REPLACE FUNCTION state_hoard.state_hd_insert()
RETURNS trigger AS
$BODY$
BEGIN
-- Implicit timestamp setting, if it's omitted
NEW.timestamp := COALESCE( NEW.timestamp,
EXTRACT('epoch' FROM CURRENT_TIMESTAMP) );
RETURN NEW;
END;
$BODY$
LANGUAGE 'plpgsql' VOLATILE
COST 100;
CREATE TRIGGER state_hd__insert
BEFORE INSERT
ON state_hoard.state_http_delay
FOR EACH ROW
EXECUTE PROCEDURE state_hoard.state_hd_insert();
After that comes the logging part, and the logged part is http response codes.
These shouldn't change frequently, so it's only logical to write changes-only
log.
To grind out random errors I write a longer-than-poll-time (10 minutes,
actually) averages to the intermediate table, while keeping track of such
errors anyway, but in separate log table.
CREATE TABLE state_hoard.log_http_availability (
"domain" character varying(128) NOT NULL,
code integer,
"timestamp" numeric NOT NULL,
CONSTRAINT log_ha__domain_timestamp PRIMARY KEY (domain, "timestamp") );
Interval for these averages can be acquired via simple rounding, and it's
convenient to have single function for that, plus the step in retriveable
form. "Immutable" type here means that the results will be cached for each set
of parameters.
CREATE OR REPLACE FUNCTION state_hoard.log_ha_step()
RETURNS integer AS
'SELECT 600;'
LANGUAGE 'sql' IMMUTABLE
COST 100;
CREATE OR REPLACE FUNCTION state_hoard.log_ha_discrete_time(numeric)
RETURNS numeric AS
'SELECT (div($1, state_hoard.log_ha_step()::numeric) + 1) * state_hoard.log_ha_step();'
LANGUAGE 'sql' IMMUTABLE
COST 100;
"Averaging" for the logs is actually just dropping errors if there's at least
one success in the interval.
It's only logical to do this right on insert into the log-table:
CREATE OR REPLACE FUNCTION state_hoard.log_ha_coerce()
RETURNS trigger AS
$BODY$
DECLARE
updated integer;
BEGIN
-- Implicit timestamp setting, if it's omitted
NEW.timestamp := state_hoard.log_ha_discrete_time(
COALESCE( NEW.timestamp,
EXTRACT('epoch' FROM CURRENT_TIMESTAMP) )::numeric );
IF NEW.code = 200
THEN
-- Successful probe overrides (probably random) errors
UPDATE state_hoard.log_http_availability
SET code = NEW.code
WHERE domain = NEW.domain AND timestamp = NEW.timestamp;
GET DIAGNOSTICS updated = ROW_COUNT;
ELSE
-- Errors don't override anything
SELECT COUNT(*)
FROM state_hoard.log_http_availability
WHERE domain = NEW.domain AND timestamp = NEW.timestamp
INTO updated;
END IF;
-- True for first value in a new interval
IF updated = 0
THEN RETURN NEW;
ELSE RETURN NULL;
END IF;
END;
$BODY$
LANGUAGE 'plpgsql' VOLATILE
COST 100;
CREATE TRIGGER log_ha__coerce
BEFORE INSERT
ON state_hoard.log_http_availability
FOR EACH ROW
EXECUTE PROCEDURE state_hoard.log_ha_coerce();
The only thing left at this point is to actually tie this intermediate log-table
with the state-table, and after-insert/update hooks are good place for that.
CREATE OR REPLACE FUNCTION state_hoard.state_ha_log()
RETURNS trigger AS
$BODY$
DECLARE
domain_var character varying (128);
code_var integer;
-- Timestamp of the log entry, explicit to get the older one, checking for random errors
ts numeric := state_hoard.log_ha_discrete_time(EXTRACT('epoch' FROM CURRENT_TIMESTAMP));
BEGIN
SELECT domain FROM state_hoard.list_http_availability
WHERE id = NEW.check_id INTO domain_var;
SELECT code FROM state_hoard.log_http_availability
WHERE domain = domain_var AND timestamp = ts
INTO code_var;
-- This actually replaces older entry, see log_ha_coerce hook
INSERT INTO state_hoard.log_http_availability (domain, code, timestamp)
VALUES (domain_var, NEW.code, ts);
-- Random errors' trapping
IF code_var != NEW.code AND (NEW.code > 400 OR code_var > 400) THEN
code_var = CASE WHEN NEW.code > 400 THEN NEW.code ELSE code_var END;
INSERT INTO state_hoard.log_http_random_errors (domain, code)
VALUES (domain_var, code_var);
END IF;
RETURN NULL;
END;
$BODY$
LANGUAGE 'plpgsql' VOLATILE
COST 100;
CREATE TRIGGER state_ha__log_insert
AFTER INSERT
ON state_hoard.state_http_availability
FOR EACH ROW
EXECUTE PROCEDURE state_hoard.state_ha_log();
CREATE TRIGGER state_ha__log_update
AFTER UPDATE
ON state_hoard.state_http_availability
FOR EACH ROW
EXECUTE PROCEDURE state_hoard.state_ha_log();
From here, the log will get populated already, but in a few days it will get
millions of entries and counting, so it have to be aggregated and the most
efficient method for this sort of data seem to be in keeping just change-points
for return codes since they're quite rare.
"Random errors" are trapped here as well and stored to the separate table. They
aren't frequent, so no other action is taken there.
The log-diff table is just that - code changes. "code_prev" field is here for
convenience, since I needed to get if there were any changes for a given period,
so the rows there would give complete picture.
CREATE TABLE state_hoard.log_http_availability_diff (
"domain" character varying(128) NOT NULL,
code integer,
code_prev integer,
"timestamp" numeric NOT NULL,
CONSTRAINT log_had__domain_timestamp PRIMARY KEY (domain, "timestamp") );
Updates to this table happen on cron-basis and generated right inside the db,
thanks to plpgsql for that.
LOCK TABLE log_http_availability_diff IN EXCLUSIVE MODE;
LOCK TABLE log_http_availability IN EXCLUSIVE MODE;
INSERT INTO log_http_availability_diff
SELECT * FROM log_ha_diff_for_period(NULL, NULL)
AS data(domain character varying, code int, code_prev int, timestamp numeric);
TRUNCATE TABLE log_http_availability;
And the diff-generation code:
CREATE OR REPLACE FUNCTION state_hoard.log_ha_diff_for_period(ts_min numeric, ts_max numeric)
RETURNS SETOF record AS
$BODY$
DECLARE
rec state_hoard.log_http_availability%rowtype;
rec_next state_hoard.log_http_availability%rowtype;
rec_diff state_hoard.log_http_availability_diff%rowtype;
BEGIN
FOR rec_next IN
EXECUTE 'SELECT domain, code, timestamp
FROM state_hoard.log_http_availability'
|| CASE WHEN NOT (ts_min IS NULL AND ts_max IS NULL) THEN
' WHERE timestamp BETWEEN '||ts_min||' AND '||ts_max ELSE '' END ||
' ORDER BY domain, timestamp'
LOOP
IF NOT rec_diff.domain IS NULL AND rec_diff.domain != rec_next.domain THEN
-- Last record for this domain - skip unknown vals and code change check
rec_diff.domain = NULL;
END IF;
IF NOT rec_diff.domain IS NULL
THEN
-- Time-skip (unknown values) addition
rec_diff.timestamp = state_hoard.log_ha_discrete_time(rec.timestamp + 1);
IF rec_diff.timestamp < rec_next.timestamp THEN
-- Map unknown interval
rec_diff.code = NULL;
rec_diff.code_prev = rec.code;
RETURN NEXT rec_diff;
END IF;
-- rec.code here should be affected by unknown-vals as well
IF rec_diff.code != rec_next.code THEN
rec_diff.code_prev = rec_diff.code;
rec_diff.code = rec_next.code;
rec_diff.timestamp = rec_next.timestamp;
RETURN NEXT rec_diff;
END IF;
ELSE
-- First record for new domain or whole loop (not returned)
-- RETURN NEXT rec_next;
rec_diff.domain = rec_next.domain;
END IF;
rec.code = rec_next.code;
rec.timestamp = rec_next.timestamp;
END LOOP;
END;
$BODY$
LANGUAGE 'plpgsql' VOLATILE
COST 100
ROWS 1000;
So that's the logging into the database.
Not as nice and simple as rrd but much more flexible in the end.
And since PostgreSQL already
allows to hook up PL/Python, there's no
problem adding a few triggers to the log-diff table to send out notifications
in case there's a problem.
Whether it's wise to put all the logic into the database like that is a good
question though, I'd probably opt for some sort of interface on the database
-> outside-world path, so db queries won't have full-fledged scripting
language at their disposal and db event handlers would be stored on the file
system, where they belong, w/o tying db to the host that way.
Apr 10, 2010
Lately I've migrated back to
pidgin from
gajim through
jabber.el. The thing which made it necessary
was XFire support (via
gfire plugin), which I've
needed to communicate w/ my
spring clanmates.
I'd have preferred jabber-xfire transport instead, but most projects there
look abandoned and I don't really need extensive jabber-features support, so
pidgin is fine with me.
The only thing that's not working there is auto-away support, so it can change
my status due to inactivity.
Actually it changes the status to "away" but for no reason at all, regardless
of idle time, and refuses to set it back to active even when I click it's
window and options.
Well, good thing is that pidgin's mature enough to have dbus interface, so as
the most problems in life, this one can be solved with python ;)
First thing to check is
pidgin dbus interface and figure out how the states
work there: you have to create a "state" with the appropriate message or find
it among stored ones then set it as active, storing id of the previous one.
Next thing is to determine a way to get idle time.
Luckily, X keeps track of activity and I've already used
xprintidle with jabber.el,
so it's not a problem.
Not quite a native py solution, but it has workaround for
one bug and is much more
liteweight than code using py-xlib.
From there it's just an endless sleep/check loop with occasional dbus calls.
One gotcha there is that pidgin can die or be closed, so the loop has to deal
with this as well.
All there is...
Get idle time:
def get_idle():
proc = Popen(['xprintidle'], stdout=PIPE)
idle = int(proc.stdout.read().strip()) // 1000
proc.wait()
return idle
Simple dbus client code:
pidgin = dbus.SessionBus().get_object(
'im.pidgin.purple.PurpleService', '/im/pidgin/purple/PurpleObject' )
iface = dbus.Interface(pidgin, 'im.pidgin.purple.PurpleInterface')
Get initial (available) status:
st = iface.PurpleSavedstatusGetCurrent()
st_type = iface.PurpleSavedstatusGetType(st)
st_msg = iface.PurpleSavedstatusGetMessage(st)
Create away/na statuses:
st_away = iface.PurpleSavedstatusNew('', status.away)
iface.PurpleSavedstatusSetMessage(
st_away, 'AFK (>{0}m)'.format(optz.away // 60) )
st_na = iface.PurpleSavedstatusNew('', status.xaway)
iface.PurpleSavedstatusSetMessage(
st_na, 'AFK for quite a while (>{0}m)'.format(optz.na // 60) )
And the main loop:
while True:
idle = get_idle()
if idle > optz.away:
if idle > optz.na:
iface.PurpleSavedstatusActivate(st_na)
log.debug('Switched status to N/A (idle: {0})'.format(idle//60))
else:
iface.PurpleSavedstatusActivate(st_away)
log.debug('Switched status to away (idle: {0})'.format(idle//60))
sleep(optz.poll)
else:
if iface.PurpleSavedstatusGetType(
iface.PurpleSavedstatusGetCurrent() ) in (status.away, status.xaway):
iface.PurpleSavedstatusActivate(st)
log.debug('Restored original status (idle: {0})'.format(idle//60))
sleep(optz.away)
Bonus of such approach is that any other checks can be easily added -
fullscreen-video-status, for example, or emacs-dont-disturb status. I bet there
are other plugins for this purposes, but I'd prefer few lines of clean py to
some buggy .so anytime ;)
Here's the full code.
Mar 10, 2010
Docks.
You always have the touch-sensitive, solid, reliable dock right under your
hands - the keyboard, so what's the point of docks?
- Mouse-user-friendly
- Look cool (cairo-dock, kiba-dock, macosx)
- Provide control over the launched instances of each app
Two first points I don't care much about, but the last one sounds really
nice - instead of switching to app workspace, you can just push the same
hotkey and it'll even be raised for you in case WS is messed up with stacked
windows.
Kinda excessive to install a full-fledged dock for just that, besides it'd eat
screen space and resources for no good reason, so I made my own "dock".
But it's not really a "dock", since it's actually invisible and basically is
just a wrapper for launched commands to check if last process spawned by
identical command exists and just bring it to foreground in this case.
For reliable monitoring of spawned processes there has to be a daemon and
wrappers should relay either command (and env) or spawned process info to it,
which inplies some sort of IPC.
Choosing dbus as that IPC handles the details like watcher-daemon starting and
serialization of data and makes the wrapper itself quite liteweight:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
dbus_iface = 'net.fraggod.SID'
dbus_path = '/net/fraggod/SID'
import os, sys, dbus
sid = dbus.SessionBus().get_object(dbus_iface, dbus_path)
if sys.argv[1][0] != '/':
for path in os.getenv('PATH').split(os.pathsep):
path = os.path.join(path, sys.argv[1])
if os.path.exists(path):
sys.argv[1] = path
break
sid.instance_request(sys.argv[1:], dict(os.environ))
And that's it, most of these just resolves binary location via PATH so it can be
used as unique-index in daemon process right off the pipe.
Daemonized part of the scheme just takes the instance off it's stack, fires up a
new one or returs back some error message:
@dbus.service.method( dbus_iface,
in_signature='asa{ss}', out_signature='s' )
def instance_request(self, argz, env):
try:
data = self.pop_instance(argz, env)
return data if data else ''
except Exception, err: return 'ERROR: {0}'.format(err)
def pop_instance(self, argz, env):
ps = argz[0]
log.info('InstanceRequest: {0}'.format(argz))
if ps[0] != '/': raise TypeError, 'App path must be absolute'
ps = os.path.realpath(ps)
log.debug('Pulling out "{0}"'.format(ps))
try:
app = self.apps[ps]
log.debug('App "{0}" exists, pulling to fg'.format(ps))
app.show()
except KeyError:
log.debug('No app "{0}", starting'.format(ps))
self.apps[ps] = AppInstance(argz, env, self.log)
return 'Started'
Dead apps are collected on SIGCHLD and some extra precautions should be taken
for the case when the signal arrives during the collector code execution, like
when several apps die simultaneously:
def reap_apps(self, sig, frm):
log.debug('Got app exit signal')
try:
locked = self.lock.acquire(False)
self.lock_req = True # indicates that apps have to be re-checked
if not locked:
log.debug('Reap is in progress, re-check scheduled')
return
while self.lock_req:
self.lock_req = False
log.debug('Reaping dead apps')
for k,app in self.apps.iteritems():
if app.dead:
del self.apps[k]
log.debug('App "{0}" was released'.format(k))
finally:
if locked: self.lock.release()
global loop_interrupt
loop_interrupt = True
log.debug('Reaper done')
That way, collector should run until signals stop arriving and shouldn't miss
any app under any circumstances.
AppInstance objects incapsulate all operations concerning each app from starting
it to focus and waitpid:
class AppInstance(object):
_id = None # for debugging purposes only
_ps = _win = None
def __init__(self, argz, env, logfile=False):
log.debug('Creating instance with argz: {0}'.format(argz))
self._id = argz[0]
self._ps = exe.proc( *argz,
preexec_fn=os.setsid, env=env,
stdout=logfile, stderr=exe.STDOUT, stdin=False )
def show(self):
if self.windows:
for win in self.windows: win.focus()
else: log.debug('No window for app "{0}"'.format(self._id))
@property
def windows(self):
if self._win is None:
self._win = wm.Window.by_pid(self._ps.pid)
if self._win: self._win = list(self._win) # all windows for pid
else: self._win = False
return self._win
@property
def dead(self):
return self._ps.wait(0) is not None
WM ops here are from fgc package.
From here all that's left to code is to create dbus-handler instance and get
the loop running.
I called the daemon itself as "sid" and the wrapper as "sic".
To make dbus aware of the service, short note should be put to
"/usr/share/dbus-1/services/net.fraggod.SID.service" with path to daemon binary:
[D-BUS Service]
Name=net.fraggod.SID
Exec=/usr/libexec/sid
...plus the hotkeys rebound from "myapp" to just "sic myapp" and the key-dock is
ready.
Works especially well with WMs that can keep app windows' props between
launches, so just pressing the relevant keys should launch every app where it
belongs with correct window parameters and you won't have to do any WM-related
work at all.
Code: sic.py sid.py
What can be more user-friendly than that? Gotta think about it...
Feb 28, 2010
Since I've put some two-day effort into creation of net-snmp snmpd extension and had some free time to
report bug in source of this inspiration, thought I might as well save
someone trouble of re-inventing the wheel and publish it somewhere, since snmpd
extension definitely looks like a black area from python perspective.
I've used sf.net as a project admin before, publishing some
crappy php code for hyscar project
with pretty much the same reasons in mind, and I didn't like the experience
much - cvs for code storage and weird interface are among the reasons I can
remember, but I'll gladly take all this criticism back - current interface has
by far exceed all my expectations (well, prehaps they were too low in the first
place?).
Putting up a full-fledged project page took me (a complete n00b at that) about
half an hour, everything being simple and obvious as it is, native-to-me git
vcs, and even trac
among the (numerous) features. Damn pleasant xp, making you wanna upload
something else just for the sake of it ;)
Just an alpha right now, but I'll polish and deploy it in production in a day
or two, so no worries.
Feb 26, 2010
Everyone who uses OSS desktop these days probably seen libnotify magic in action - small popup windows that
appear at some corner of the screen, announcing events from other apps.
libnotify itself, however, is just a convenience lib for dispatching these
notifications over dbus, so the latter can pass it app listening on this
interface or even start it beforehand.
Standard app for rendering such messages is notification-daemon, which is
developed alongside with libnotify, but there are drop-in replacements like
xfce4-notifyd or
e17
notification module. In dbus rpc mechanism
call signatures are clearly defined and visible, so it's pretty easy to
implement replacement for aforementioned daemons, plus vanilla
notification-daemon has introspection calls and dbus itself can be easily
monitored (via dbus-monitor utility) which make it's implementation even more
transparent.
Now, polling every window for updates manually is quite inefficient - new
mail, xmpp messages, IRC chat lines, system events etc sometimes arrive every
few seconds, and going over all the windows (and by that I mean workspaces
where they're stacked) just to check them is a huge waste of time, especially
when some (or even most, in case of IRC) of these are not really important.
Either response time or focus (and, in extreme case, sanity) has to be
sacrificed in such approach. Luckily, there's another way to monitor this
stuff - small pop-up notifications allow to see what's happening right away,
w/o much attention-switching or work required from an end-user.
But that's the theory.
In practice, I've found that enabling notifications in IRC or jabber is pretty
much pointless, since you'll be swarmed by these as soon as any real activity
starts there. And w/o them it's a stupid wasteful poll practice, mentioned
above.
Notification-daemon has no tricks to remedy the situation, but since the whole
thing is so abstract and transparent I've had no problem making my own fix.

Solution I came up with is to batch the notification messages into a digests as
soon as there are too many of them, displaying such digest pop-ups with some
time interval, so I can keep a grip on what's going on just by glancing at these
as they arrive, switching my activities if something there is important enough.
Having played with schedulers and network shaping/policing before, not much
imagination was required to devise a way to control the message flow rate.
I chose
token-bucket algorithm
at first, but since prolonged flood of I-don't-care-about activity have
gradually decreasing value, I didn't want to receive digests of it every N
seconds, so I batched it with a gradual digest interval increase and
leaky-bucket mechanism, so
digests won't get too fat over these intervals.
Well, the result exceeded my expectations, and now I can use libnotify freely
even to indicate that some rsync just finished in a terminal on another
workspace. Wonder why such stuff isn't built into existing notification
daemons...
Then, there was another, even more annoying issue: notifications during
fullscreen apps! WTF!?
Wonder if everyone got used to this ugly flickering in fullscreen mplayer,
huge lags in GL games like SpringRTS or I'm just re-inventing the wheel here,
since it's done in gnome or kde (knotify, huh?), but since I'm not gonna use
either one I just added
fullscreen-app check before notification
output, queueing them to digest if that is the case.
Ok, a few words about implementation.
Token bucket itself is based on
activestate recipe with some heavy improvements
to adjust flow on constant under/over-flow, plus with a bit more pythonic
style and features, take a look
here. Leaky bucket
implemented by
this class.
Main dbus magic, however, lies outside the script, since dbus calls cannot be
intercepted and the scheduler can't get'em with notification-daemon already
listening on this interface.
Solution is easy, of course - scheduler can
replace the real daemon
and proxy mangled calls to it as necessary. It takes
this sed line
for notification-daemon as well, since interface is hard-coded there.
Needs
fgc module, but it's just a hundred
lines on meaningful code.
One more step to making linux desktop more comfortable. Oh, joy ;)
Feb 17, 2010
Having seen people really obsessed with the music, I don't consider myself to be
much into it, yet I've managed to accumulate more than 70G of it, and
counting. That's probably because I don't like to listen to something on a loop
over and over, so, naturally, it's quite a bother to either keep the collection
on every machine I use or copy the parts of it just to listen and replace.
Ideal solution for me is to mount whole hoard right from home server, and
mounting it over the internet means that I need some kind of authentication.
Since I also use it at work, encryption is also nice, so I can always pass
this bandwith as something work-friendly and really necessary, should it
arouse any questions.
And while bandwith at work is pretty much unlimited, it's still controlled, so
I wouldn't like to overuse it too much, and listening to oggs, mp3 and flacs
for the whole work-day can generate traffic of 500-800 megs, and that's quite
excessive to that end, in my own estimation.
The easiest way for me was trusty sshfs - it's got the best authentication, nice
performance and encryption off-the-shelf with just one simple command. Problem
here is the last aforementioned point - sshfs would generate as much bandwith as
possible, caching content only temporarily in volatile RAM.
Persistent caching seem to be quite easy to implement in userspace with either
fuse layer over network filesystem or something even simpler (and more hacky),
like aufs and inotify, catching IN_OPEN events and pulling files in question to
intermediate layer of fs-union.
Another thing I've considered was fs-cache in-kernel mechanism, which appeared
in the main tree since around 2.6.30, but the bad thing about was that while
being quite efficient, it only worked for NFS or AFS.
Second was clearly excessive for my purposes, and the first one I've come to
hate for being extremely ureliable and limiting. In fact, NFS never gave me
anything but trouble in the past, yet since I haven't found any decent
implementations of the above ideas, I'd decided to give it (plus fs-cache) a
try.
Setting up nfs server is no harder than sharing dir on windows - just write a
line to /etc/exports and fire up nfs initscript. Since nfs4 seems superior
than nfs in every way, I've used that version.
Trickier part is authentication. With nfs' "accept-all" auth model and
kerberos being out of question, it has to be implemented on some transport
layer in the middle.
Luckily, ssh is always there to provide a secure authenticated channel and nfs
actually supports tcp these days. So the idea is to start nfs on localhost on
server and use ssh tunnel to connecto to it from the client.
Setting up tunnel was quite straightforward, although I've put together a simple
script to avoid re-typing the whole thing and to make sure there aren't any dead
ssh processes laying around.
#!/bin/sh
PID="/tmp/.$(basename $0).$(echo "$1.$2" | md5sum | cut -b-5)"
touch "$PID"
flock -n 3 3<"$PID" || exit 0
exec 3>"$PID"
( flock -n 3 || exit 0
exec ssh\
-oControlPath=none\
-oControlMaster=no\
-oServerAliveInterval=3\
-oServerAliveCountMax=5\
-oConnectTimeout=5\
-qyTnN $3 -L "$1" "$2" ) &
echo $! >&3
exit 0
That way, ssh process is daemonized right away. Simple locking is also
implemented, based on tunnel and ssh destination, so it might be put as a
cronjob (just like "ssh_tunnel 2049:127.0.0.1:2049 user@remote") to keep the
link alive.
Then I've put a line like this to /etc/exports:
/var/export/leech 127.0.0.1/32(ro,async,no_subtree_check,insecure)
...and tried to "mount -t nfs4 localhost:/ /mnt/music" on the remote.
Guess what? "No such file or dir" error ;(
Ok, nfs3-way to "mount -t nfs4 localhost:/var/export/leech /mnt/music" doesn't
work as well. No indication of why it is whatsoever.
Then it gets even better - "mount -t nfs localhost:/var/export/leech
/mnt/music" actually works (locally, since nfs3 defaults to udp).
Completely useless errors and nothing on the issue in manpages was quite
weird, but prehaps I haven't looked at it well enough.
Gotcha was in the fact that it wasn't allowed to mount nfs4 root, so tweaking
exports file like this...
/var/export/leech 127.0.0.1/32(ro,async,no_subtree_check,insecure,fsid=0)
/var/export/leech/music 127.0.0.1/32(ro,async,no_subtree_check,insecure,fsid=1)
...and "mount -t nfs4 localhost:/music /mnt/music" actually solved the issue.
Why can't I use one-line exports and why the fuck it's not on the first (or
any!) line of manpage escapes me completely, but at least it works now even from
remote. Hallelujah.
Next thing is the cache layer. Luckily, it doesn't look as crappy as nfs and
tying them together can be done with a single mount parameter. One extra thing
needed, aside from the kernel part, here, is cachefilesd.
Strange thing it's not in gentoo portage yet (since it's kinda necessary for
kernel mechanism and quite aged already), but there's an
ebuild in b.g.o (now mirrored to my overlay,
as well).
Setting it up is even simpler.
Config is well-documented and consists of five lines only, the only relevant
of which is the path to fs-backend, oh, and the last one seem to need
user_xattr support enabled.
fstab lines for me were these:
/dev/dump/nfscache /var/fscache ext4 user_xattr
localhost:/music /mnt/music nfs4 ro,nodev,noexec,intr,noauto,user,fsc
First two days got me 800+ megs in cache and from there it was even better
bandwidth-wise, so, all-in-all, this nfs circus was worth it.
Another upside of nfs was that I could easily share it with workmates just by
binding ssh tunnel endpoint to a non-local interface - all that's needed from
them is to issue the mount command, although I didn't came to like to
implementation any more than I did before.
Wonder if it's just me, but whatever...
Feb 14, 2010
According to the general plan, with
backed-up side scripts in place,
some backup-grab mechanism is needed on the backup host.
So far, sshd provides secure channel and authentication, launching control
script as a shell, backed-up side script provides hostname:port for one-shot ssh
link on the commandline, with private key to this link and backup-exclusion
paths list piped in.
All that's left to do on this side is to read the data from a pipe and start
rsync over this link, with a few preceding checks, like a free space check, so
backup process won't be strangled by its abscence and as many as possible
backups will be preserved for as long as possible, removing them right before
receiving new ones.
Historically, this script also works with any specified host, interactively
logging into it as root for rsync operation, so there's bit of interactive
voodoo involved, which isn't relevant for the remotely-initiated backup case.
Ssh parameters for rsync transport are passed to rsync itself, since it starts
ssh process, via "--rsh" option. Inside the script,these are accumulated in
bak_src_ext variable
Note that in case then this script is started as a shell, user is not a root,
yet it needs to store filesystem metadata like uids, gids, acls, etc.
To that end, rsync can employ user_xattr's, although it looks extremely
unportable and inproper to me, since nothing but rsync will translate them
back to original metadata, so rsync need to be able to change fs metadata
directly, and to that end there's posix capabilities.
I use custom module for capability
manipulation, as well as other convenience modules here and there, their purpose is quite
obvious and replacing these with stdlib functions should be pretty
straightforward, if necessary.
Activating the inherited capabilities:
bak_user = os.getuid()
if bak_user:
from fgc.caps import Caps
import pwd
os.putenv('HOME', pwd.getpwuid(bak_user).pw_dir)
Caps.from_process().activate().apply()
But first things first - there's data waiting on commandline and stdin. Getting
the hostname and port...
bak_src = argz[0]
try: bak_src, bak_src_ext = bak_src.split(':')
except: bak_src_ext = tuple()
else: bak_src_ext = '-p', bak_src_ext
...and the key / exclusions:
bak_key = bak_sub('.key_{0}'.format(bak_host))
password, reply = it.imap(
op.methodcaller('strip', spaces), sys.stdin.read().split('\n\n\n', 1) )
open(bak_key, 'w').write(password)
sh.chmod(bak_key, 0400)
bak_src_ext += '-i', os.path.realpath(bak_key)
Then, basic rsync invocation options can be constructed:
sync_optz = [ '-HaAXz',
('--skip-compress='
r'gz/bz2/t\[gb\]z/tbz2/lzma/7z/zip/rar'
r'/rpm/deb/iso'
r'/jpg/gif/png/mov/avi/ogg/mp\[34g\]/flv/pdf'),
'--super',
'--exclude-from={0}'.format(bak_exclude_server),
'--rsync-path=ionice -c3 rsync',
'--rsh=ssh {0}'.format(' '.join(bak_src_ext)) ]
Excluded paths list here is written to a local file, to keep track which paths
were excluded in each backup. "--super" option is actually necessary if local
user is not root, rsync drops all the metadata otherwise. "HaAX" is like
"preserve all" flags - Hardlinks, ownership/modes/times ("a" flag), Acl's,
eXtended attrs. "--rsh" here is the ssh command, with parameters, determined
above.
Aside from that, there's also need to specify hardlink destination path, which
should be a previous backup, and that traditionnaly is the domain of ugly
perlisms - regexps.
bakz_re = re.compile(r'^([^.].*)\.\d+-\d+-\d+.\d+$') # host.YYYY-mm-dd.unix_time
bakz = list( bak for bak in os.listdir(bak_root)
if bakz_re.match(bak) ) # all backups
bakz_host = sorted(it.ifilter(op.methodcaller(
'startswith', bak_host ), bakz), reverse=True)
So, the final sync options come to these:
src = '{0}:/'.format(src)
sync_optz = list(dta.chain( sync_optz, '--link-dest={0}'\
.format(os.path.realpath(bakz_host[0])), src, bak_path ))\
if bakz_host else list(dta.chain(sync_optz, src, bak_path))
The only interlude is to cleanup backup partition if it gets too crowded:
## Free disk space check / cleanup
ds, df = sh.df(bak_root)
min_free = ( max(min_free_avg( (ds-df) / len(bakz)), min_free_abs*G)
if min_free_avg and bakz else min_free_abs*G )
def bakz_rmq():
'''Iterator that returns bakz in order of removal'''
bakz_queue = list( list(bakz) for host,bakz in it.groupby(sorted(bakz),
key=lambda bak: bakz_re.match(bak).group(1)) )
while bakz_queue:
bakz_queue.sort(key=len)
bakz_queue[-1].sort(reverse=True)
if len(bakz_queue[-1]) <= min_keep: break
yield bakz_queue[-1].pop()
if df < min_free:
for bak in bakz_rmq():
log.info('Removing backup: {0}'.format(bak))
sh.rr(bak, onerror=False)
ds, df = sh.df(bak_root)
if df >= min_free: break
else:
log.fatal( 'Not enough space on media:'
' {0:.1f}G, need {1:.1f}G, {2} backups min)'\
.format( op.truediv(df, G),
op.truediv(min_free, G), min_keep ), crash=2 )
And from here it's just to start rsync and wait 'till the job's done.
This thing works for months now, and saved my day on many occasions, but the
most important thing here I think is the knowledge that the backup is there
should you need one, so you never have to worry about breaking your system or
losing anything important there, whatever you do.
Here's the full script.
Actually, there's more to the story, since just keeping backups on single
local harddisk (raid1 of two disks, actually) isn't enough for me.
Call this paranoia, but setting up system from scratch and restoring all the
data I have is a horrible nightmare, and there are possibility of fire,
robbery, lighting, voltage surge or some other disaster that can easily take
this disk(s) out of the picture, and few gigabytes of space in the web come
almost for free these days - there are p2p storages like wuala, dropbox,
google apps/mail with their unlimited quotas...
So, why not upload all this stuff there and be absolutely sure it'd
never go down, whatever happens? Sure thing.
Guess I'll write a note on the topic as much to document it for myself as for
the case someone might find it useful as well, plus the ability to link it
instead of explaining ;)
Feb 13, 2010
As I've already outlined before, my idea
of backups comes down to these points:
- No direct access to backup storage from backed-up machine, no knowledge about
backup storage layout there.
- No any-time access from backup machine to backed-up one. Access should be
granted on the basis of request from backed-up host, for one connection only.
- Read-only access to filesystem only, no shell or network access.
- Secure transfer channel.
- Incremental, yet independent backups, retaining all fs metadata.
- No extra strain on network (wireless) or local disk space.
- Non-interactive usage (from cron).
- No root involved on any side at any time.
And the idea is to implement these with openssh, rsync and a pair of scripts.
Ok, the process is initiated by backed-up host, which will spawn sshd for single
secure backup channel, so first thing to do is to invoke of ssh-keygen and get
the pair of one-time keys from it.
As an extra precaution, there's no need to write private key to local
filesystem, as it's only needed by ssh-client on a remote (backup) host.
Funny thing is that ssh-keygen doesn't actually allow that, although it's
possible to make it use fifo socket instead of file.
FIFO socket implies blocking I/O however, so one more precaution should be
taken for script not to hang indefinitely.
A few convenience functions here and there are imported from fgc module, but can be replaced by standard
counterparts (POpen, unlink, etc) without problem - no magic there.
Here we go:
def unjam(sig, frm):
raise RuntimeError, 'no data from ssh-keygen'
signal.signal(signal.SIGALRM, unjam)
os.mkfifo(key)
keygen = exe.proc( 'ssh-keygen', '-q',
'-t', 'rsa', '-b', '2048', '-N', '', '-f', key )
signal.alarm(5)
key_sub = open(key).read()
sh.rm(key, onerror=False)
if keygen.wait(): raise RuntimeError, 'ssh-keygen has failed'
signal.alarm(0)
Public key can then be used to generate one-time ACL file, aka
"authorized_hosts" file:
keygen = open(key_pub, 'r').read().strip(spaces)
open(key_pub, 'w').write(
'from="{0}" {1}\n'.format(remote_ip, keygen) )
So, we have an ACL file and matching private key. It's time to start sshd:
sshd = exe.proc( '/usr/sbin/sshd', '-6', '-de', '-p{0}'.format(port),
'-oChallengeResponseAuthentication=no', # no password prompt
'-oAllowAgentForwarding=no', # no need for this
'-oAllowTcpForwarding=no', # no port-forwarding
'-oPermitTunnel=no', # no tunneling
'-oCompression=no', # minor speedup, since it's handled by rsync
'-oForceCommand=/usr/bin/ppy {0} -c'\
.format(os.path.realpath(__file__)), # enforce this script checks
'-oAuthorizedKeysFile={0}'\
.format(os.path.realpath(key_pub)), silent=True )
A bit of an explaination here.
"silent" keyword here just eats verbose stdout/stderr, since it's not needed for
these purposes.
According to original plan, I use "ForceCommand" to start the same
initiator-script (but with "-c" parameter), so it will invoke rsync (and rsync
only) with some optional checks and scheduling priority enforcements.
Plus, since initial script and sshd are started by ordinary user, we'd need to
get dac_read_search capability for rsync to be able to read (and only read)
every single file on local filesystem.
That's where
ppy binary comes in, launching
this script with additional capabilities, defined for the script file.
Script itself doesn't need to make the caps effective - just pass as inherited
further to rsync binary, and that's where it, and I mean
cap_dac_read_search, should be activated and used.
To that end, system should have aforementioned wrapper (
ppy) with permitted-effective caps, to provide
them in the first place, python binary with "cap_dac_read_search=i" and
rsync with "cap_dac_read_search=ei" (since it doesn't have option to
activate caps from it's code).
This may look like an awful lot of privileged bits, but it's absolutely not!
Inheritable caps are just that - inheritable, they won't get set by this bit
by itself.
In fact, one can think of whole fs as suid-inheritable, and here inheritance
only works for a small fragment of root's power and that only for three files,
w/o capability to propagnate anywhere else, if there'd be some exec in a bogus
commandline.
Anyway, everything's set and ready for backup host to go ahead and grab local
fs.
Note that backup of every file isn't really necessary, since sometimes most
heavy ones are just caches, games or media content, readily available for
downloading from the net, so I just glance at my fs with xdiskusage tool (which
is awesome, btw, even for remote servers' df monitoring: "ssh remote du -k / |
xdiskusage") to see if it's in need of cleanup and to add largest paths to
backup-exclude list.
Actually, I thought of dynamically excluding pretty much everything that can be
easily rebuilt by package manager (portage in my case), but decided
that I have space for these, and backing it all up makes "rm -rf", updates or
compiler errors (since I'm going to try icc) much less scary
anyway.
Ok, here goes the backup request:
ssh = exe.proc( 'ssh', remote,
'{0}:{1}'.format(os.uname()[1], port), stdin=exe.PIPE )
ssh.stdin.write(key_sub)
ssh.stdin.write('\n\n\n')
ssh.stdin.write(open('/etc/bak_exclude').read())
ssh.stdin.close()
if ssh.wait(): raise RuntimeError, 'Remote call failed'
"remote" here is some unprivileged user on a backup host with backup-grab script
set as a shell. Pubkey auth is used, so no interaction is required.
And that actually concludes locally-initiated operations - it's just wait to
confirm that the task's completed.
Now backup host have the request, to-be-backed-up hostname and port on the
commandline, with private key and paths-to-exclude list piped through.
One more thing done locally though is the invocation of this script when backup
host will try to grab fs, but it's simple and straightforward as well:
cmd = os.getenv('SSH_ORIGINAL_COMMAND')
if not cmd: parser.error('No SSH_ORIGINAL_COMMAND in ENV')
if not re.match(
r'^(ionice -c\d( -n\d)? )?rsync --server', cmd ):
parser.error('Disallowed command: {0}'.format(cmd))
try: cmd, argz = cmd.split(' ', 1)
except ValueError: argz = ''
os.execlp(cmd, os.path.basename(cmd), *argz.split())
Rsync takes control from here and reads fs tree, checking files and their
attributes against previous backups with it's handy rolling-checksums, creating
hardlinks on match and transferring only mismatching pieces, if any, but more on
that later, in the next post about implementation of the other side of this
operation.
Full version of this script can be found here.
Feb 11, 2010
There's saying: "there are two kinds of sysadmins - the ones that aren't making
backups yet, and the ones that already do". I'm not sure if the essence of the
phrase wasn't lost in translation (ru->eng), but the point is that it's just a
matter of time, 'till you start backing-up your data.
Luckily for me, I've got it quite fast, and consider making backups on a daily
basis is a must-have practice for any developer/playground machine or
under-development server. It saved me on a countless occasions, and there were
quite a few times when I just needed to check if everything in my system is
still in place and were there before.
Here I'll try to describe my sample backup system operation and the reasons for
building it like that.
Ok, what do I need from the backup ecosystem?
- Obviously, it'd be a bother to backup each machine manually every day, so
there's a cron.
- Backing up to the same machine obviously isn't a good idea, so the backup has
to be transferred to remote system, preferrably several ones, in different
environments.
- Another thing to consider is the size of such backups and efficient method of
storage, transfer and access to them.
- Then there's a security issue - full fs read capabilities are required to
create the backup, and that can be easily abused.
First two points suggest that you either need privileged remote access to the
machine (like root ssh, which is a security issue) or make backups (local fs
replicas) locally then transfer them to remote with unprivileged access (just to
these backups).
Local backups make third point (space efficiency) more difficult, since you
either have to make full backups locally (and transferring them, at the very
least, is not-so-efficient at all) or keep some metadata about the state of all
the files (like "md5deep -r /", but with file metadata checksums as well), so
you can efficiently generate increments.
Traditional hacky way to avoid checksumming is to look at inode mtimes only, but
that is unreliable, especially so, since I like to use stuff like "cp -a" and
"rsync -a" (synchronises timestamps) on a daily basis and play with timestamps
any way I like to.
Space efficiency usually achieved via incremental archives. Not really my thing,
since they have terrible accessibility - tar (and any other streaming formats
like cpio) especially, dar less so, since it has
random access and file subset merge features, but still bad at keeping
increments (reference archive have to be preserved, for one thing) and is not
readily-browseable - you have to unpack it to some tmp path before doing
anything useful with files. There's also SquashFS, which is sorta "browsable archive", but it
has not increment-tracking features at all ;(
Another way to preserve space is to forget about these archive formats and
just use filesystem to store backed-up tree. Compression is also an option
here with ZFS or Btrfs or some FUSE layer like
fusecompress, keeping increments is also simple with
either hardlinks or snapshots.
Obviously, accessibility (and simplicity, btw) here is next to nothing, and
you can use diff, rsync and rest of the usual tools to do anything you want
with it, which I see as a great feat. And should you need to transfer it in a
container - just tar it right to the medium in question.
Of course, I liked this way a lot more than the archives, and decided to stick
with it.
So, at this point the task was refined to just rsync from backed-up
machine to backup storage.
Since I have two laptops which mightn't always be accessible to backup host
and should be able to initiate backup when I need to without much effort, it's
best if the backups are initiated from backed-up machine.
That said...
- I don't want to have any kind of access to backup storage from this machine or
know anything about backup storage layout, so direct rsync to storage is out
of question.
- At the same time, I don't need any-time root - or any other kind of - access
to local machine form backup host, I only need it when I do request a backup
locally (or local cron does it for me).
- In fact, even then, I don't need backup host to have anything but read-only
access to local filesystem. This effectively obsoletes the idea of
unprivileged access just-to-local-backups, since they are the same read-only
(...replicas of...) local filesystem, so there's just no need to make them.
Obvious tool for the task is rsync-pull, initiated from backup host (and
triggered by backed-up host), with some sort of one-time pass, given by the
backed-up machine.
And local rsync should be limited to read-only access, so it can't be used by
backup-host imposter to zero or corrupt local rootfs. Ok, that's quite a
paranoid scenario, especially if you can identify backup host by something like
ssh key fingerprint, but it's still a good policy.
Ways to limit local rsync to read-only, but otherwise unrestricted, access I've
considered were:
- Locally-initiated rsync with parameters, passed from backup host, like "rsync
-a / host:/path/to/storage". Not a good option, since that requres parameter
checking and that's proven to be error-prone soul-sucking task (just look at
the sudo or suid-perl), plus it'd need some one-time and restricted access
mechanism on backup host.
- Local rsyncd with one-time credentials. Not a bad way. Simple, for one thing,
but the link between the hosts can be insecure (wireless) and rsync protocol
does not provide any encryption for the passed data - and that's the whole
filesystem piped through. Also, there's no obvious way to make sure it'd
process only one connection (from backup host, just to read fs once) -
credentials can be sniffed and used again.
- Same as before, but via locally-initiated reverse-ssh tunnel to rsyncd.
- One-shot local sshd with rsync-only command restriction, one-time generated
keypair and remote ip restriction.
Last two options seem to be the best, being pretty much the same thing,
with the last one more robust and secure, since there's no need to
tamper with rsyncd and it's really one-shot.
Caveat however, is how to give rsync process read-only access. Luckily,
there's dac_read_search posix capability, which allows just that - all
that's needed is to make it inheritable-effective for rsync binary in
question, which can be separate statically-linked one, just for these backup
purposes.
Separate one-shot sshd also friendly to nice/ionice setting and traffic
shaping (since it's listening on separate port), which is quite crucial for
wireless upload bandwidth since it has a major impact on interactive
connections - output pfifo gets swarmed by ssh-data packets and every other
connection actions (say, ssh session keypress) lag until it's packets wait in
this line... but that's a bit unrelated note (see
LARTC if you don't know what it's all
about, mandatory).
And that actually concludes the overall plan, which comes to these
steps:
- Backed-up host:
- Generates ssh keypair (ssh-keygen).
- Starts one-shot sshd ("-d" option) with authorization only for generated
public key, command ("ForceCommand" option), remote ip ("from=" option) and
other (no tunneling, key-only auth, etc) restrictions.
- Connects (ssh, naturally) to backup host's unprivileged user or restricted
shell and sends it's generated (private) key for sshd auth, waits.
- Backup host:
- Receives private ssh key from backed-up host.
- rsync backed-up-host:/ /path/to/local/storage
Minor details:
- ssh pubkey authentication is used to open secure channel to a backup host,
precluding any mitm attacks, non-interactive cron-friendly.
- sshd has lowered nice/ionice and bandwidth priority, so it won't interfere
with host operation in any way.
- Backup host receives link destination for rsync along with the private key, so
it won't have to guess who requested the backup and which port it should use.
- ForceCommand can actually point to the same "backup initiator" script, which
will act as a shell with full rsync command in SSH_ORIGINAL_COMMAND env var,
so additional checks or privilege manipulations can be performed immediately
before sync.
- Minimal set of tools used: openssh, rsync and two (fairly simple) scripts on
both ends.
Phew... and I've started writing this just as an example usage of posix
capabilities for
previous entry.
Guess I'll leave implementation details for the next one.
Feb 01, 2010
I bet everyone who did any sysadmin tasks for linux/*bsd/whatever, stumbled
upon the need to elevate privileges for some binary or script.
And most of the time if there's any need for privileges at all, it's for the
ones that only root has: changing uid/gid on files, full backup, moving stuff
owned by root/other-uids, signaling daemons, network tasks, etc.
Most of these tasks require only a fragment of root's power, so capabilities(7)
is a nice way to get what you need without compromising anything. Great feat of
caps is that they aren't inherited on exec, which seem to beat most of
vulnerabilities for scripts, which don't usually suffer from C-like code
shortcomings, provided the interpreter itself is up-to-date.
However, I've found that support for capabilities in linux (gentoo in my case,
but that seem to hold true for other distros) is quite lacking. While they've
been around for quite a while, even simplest ping util still has suid bit
instead of single cap_net_*, daemons get root just to bind a socket on a
privileged port and service scripts just to send signal some pid.
For my purposes, I needed to backup FS with rsync, synchronize data between
laptops and control autofs/mounts, all that from py scripts, and using full root
for any of these tasks isn't necessary at all.
First problem is to give limited capabilities to a script.
One way to get them is to get everything from sudo or suid bit (aka get root),
then drop everything that isn't needed, which is certainly better than having
root all the time, but still excessive, since I don't need full and inheritable
root at any point.
Another way is to inherit caps from cap-enabled binary. Just like suid, but you
don't need to get all of them, they won't have to be inheritable and it doesn't
have to be root-or-nothing. This approach looks a way nicer than the first one,
so I decided to stick with it.
For py script, it means that the interpreter has to inherit some caps from
something else, since it wouldn't be wise to give caps to all py scripts
indiscriminatively. "some_caps=i" (according to libcap text representation
format, see cap_to_text(3)) or even "all=i" are certainly better.
To get caps from nothing, a simple C wrapper would suffice, but I'm a bit too
lazy to write one for every script I run so I wrote one that gets all the caps
and drops them to the subset that script file's inherited set. More on this (a
bit unrelated) subject here.
That leads to the point there py code starts with some permitted, but not
immediately effective, set of capabilities.
Tinkering with caps in C is possible via libcap and libcap-ng, and the only module for py seem
to be cap-ng bindings. And they do suck.
Not only it's a direct C calls translation, but the interface is sorely lacking
as well. Say, you need something extremely simple: to remove cap from some set,
to activate permitted caps as effective or copy them to inherited set... well,
no way to do that, what a tool. Funny thing, libcap can't do that in any obvious
way either!
So here goes my solution - dumped whole cap-manipulation interface of both libs
apart from dump-restore from/to string functions, wrote simple py-C interface to it and wrapped them in
python OO interface - Caps class.
And the resulting high-level py code to make permitted caps effective goes like
this:
Caps.from_process().activate().apply()
To make permitted caps inheritable:
caps.propagnate().apply()
And the rest of the ops is just like this:
caps['inheritable'].add('cap_dac_read_search')
caps.apply()
Well, friendly enough for me, and less than hundred lines of py code (which does
all the work apart from load-save) for that.
While the code is part of a larger toolkit (fgc), it doesn't depend on any other part of
it - just C module and py wrapper.
Of course, I was wondering why no-one actually wrote something like this before,
but looks like not many people actually use caps at all, even though it's worth
it, supported by the fact that while I've managed to find the bug in .32 and
.33-rc* kernel, preventing
prehaps one of the most useful caps (cap_dac_read_search) from working ;(
Well, whatever.
Guess I'll write more about practical side and my application of this stuff next
time.