Home-brewed NAS gluster with sensible replication
Hardware
- Two mounts instead of one. Ok, not a big deal by itself.
- I'd have to manage free space on these by hand, shuffling subtrees between them.
- I need replication for some subtrees, and that complicates the previous point a bit further.
- Some sort of HA would be nice, so I'd be able to shutdown one replica and switch to using another automatically.
The Setup
Ok, what I have is:
- Node1
- physical storage (raid1) "disk11", 300G, old and fairly "valuable" data (well, of course it's not "valuable", since I can just re-download it all from p2p, but I'd hate to do that)
- physical disk "disk12", 150G, same stuff as disk11
- Node2
- physical disk "disk2", 1.5T, blank, to-be-filled
What I want is one single network storage, with db1 (disk11 + disk12) data available from any node (replicated) and new stuff which won't fit onto this storage should be writen to db2 (what's left of disk2).
With glusterfs there are several ways to do this:
Scenario 1: fully network-aware client.
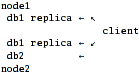
That's actually the simplest scenario - glusterfsd.vol files on "nodes" should just export local disks and client configuration ties it all together.
Pros:
- Fault tolerance. Client is fully aware of the storage hierarchy, so if one node with db1 is down, it will just use the other one.
- If the bandwidth is better than disk i/o, reading from db1 can be potentially faster (dunno if glusterfs allows that, actually), but that's not the case, since "client" is one of the laptops and it's a slow wifi link.
Cons:
- Write performance is bad - client has to push data to both nodes, and that's a
- big minus with my link.
Scenario 2: server-side replication.
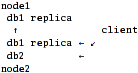
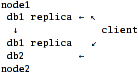
Here, "nodes" export local disks for each other and gather local+remote db1 into cluster/replicate and then export this already-replicated volume. Client just ties db2 and one of the replicated-db1 together via nufa or distribute layer.
Pros:
- Better performance.
Cons:
- Single point of failure, not only for db2 (which is natural, since it's not replicated), but for db1 as well.
Scenario 3: server-side replication + fully-aware client.
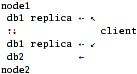
db1 replicas are synced by "nodes" and client mounts all three volumes (2 x db1, 1 x db2) with either cluster/unify layer and nufa scheduler (listing both db1 replicas in "local-volume-name") or cluster/nufa.
But there is a problem: cluster/nufa has no support for multiple local-volume-name specs. cluster/unify has this support, but requires it's ugly "namespace-volume" hack. The solution would be to aggregate both db1's into a distribute layer and use it as a single volume alongside db2.
With aforementioned physical layout this seem to be just the best all-around case.
Pros:
- Best performance and network utilization.
Cons:
- None?
Implementation
So, scenarios 2 and 3 in terms of glusterfs, with the omission of different performance, lock layers and a few options, for the sake of clarity:
node1 glusterfsd.vol:
## db1: replicated node1/node2
volume local-db1
type storage/posix
option directory /srv/storage/db1
end-volume
# No client-caches here, because ops should already come aggregated
# from the client, and the link between servers is much fatter than the client's
volume node2-db1
type protocol/client
option remote-host node2
option remote-subvolume local-db1
end-volume
volume composite-db1
type cluster/replicate
subvolumes local-db1 node2-db1
end-volume
## db: linear (nufa) db1 + db2
## export: local-db1 (for peers), composite-db1 (for clients)
volume export
type protocol/server
subvolumes local-db1 composite-db1
end-volume
node2 glusterfsd.vol:
## db1: replicated node1/node2
volume local-db1
type storage/posix
option directory /srv/storage/db1
end-volume
# No client-caches here, because ops should already come aggregated
# from the client, and the link between servers is much fatter than the client's
volume node1-db1
type protocol/client
option remote-host node1
option remote-subvolume local-db1
end-volume
volume composite-db1
type cluster/replicate
subvolumes local-db1 node1-db1
end-volume
## db2: node2
volume db2
type storage/posix
option directory /srv/storage/db2
end-volume
## db: linear (nufa) db1 + db2
## export: local-db1 (for peers), composite-db1 (for clients)
volume export
type protocol/server
subvolumes local-db1 composite-db1
end-volume
client (replicated to both nodes):
volume node1-db1
type protocol/client
option remote-host node1
option remote-subvolume composite-db1
end-volume
volume node2-db1
type protocol/client
option remote-host node2
option remote-subvolume composite-db1
end-volume
volume db1
type cluster/distribute
option remote-subvolume node1-db1 node2-db1
end-volume
volume db2
type protocol/client
option remote-host node2
option remote-subvolume db2
end-volume
volume db
type cluster/nufa
option local-volume-name db1
subvolumes db1 db2
end-volume
node# /usr/sbin/glusterfsd --debug --volfile=/etc/glusterfs/glusterfsd.vol
client# /usr/sbin/glusterfs --debug --volfile-server=somenode /mnt/tmp